
最近在学习React的时候无意中了解到JS引擎有一项性能优化手段叫Inline Caches,顿时产生浓厚的兴趣。于是研究了一番,并整理成文。
JS执行过程
目前市面上所有的JS引擎包括Chrome的V8、Mozilla的SpiderMonkey、微软的Chakra以及苹果的JSC,它们执行JS代码的过程都是类似的。 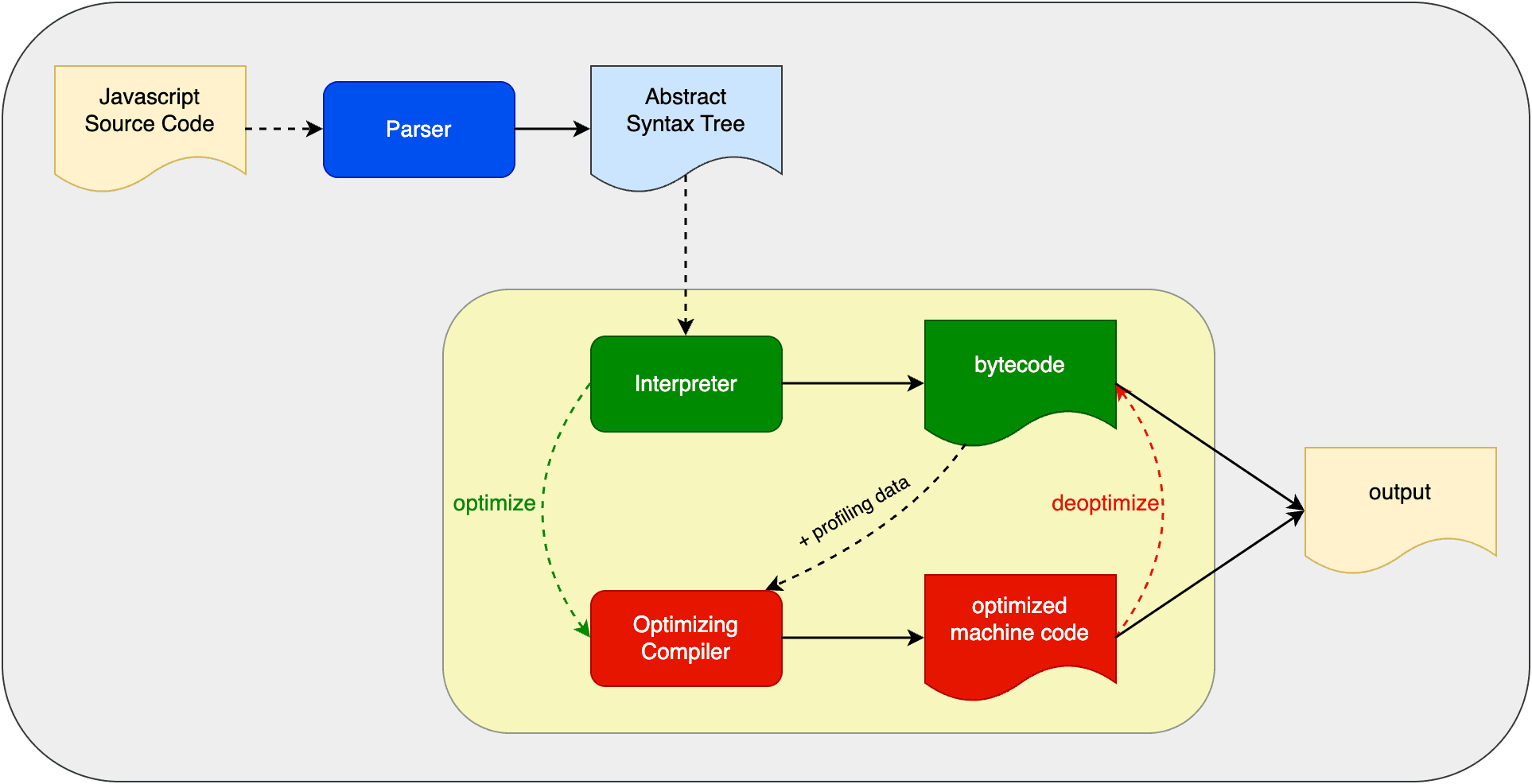 首先,JS源码经过解析器(
首先,JS源码经过解析器(Parser)的词法分析和语法分析,生成抽象语法树(AST)。然后,解释器(Interpreter)将AST转成字节码并执行。
解释器生成字节码的速度很快,但字节码的执行效率没有机器码高。
为了提升性能,JS引擎引入优化编译器(Optimizing Compiler)。优化编译器通过字节码和分析数据(Profiling Data)或者说反馈信息(Feedback)推断出可优化的点,从而生成优化的机器码,最后由CPU执行。
有的时候优化编译器的推断会产生不正确的结果,这时候会去优化(deoptimize),回到解释器,执行字节码。
虽然机器码执行效率比较高,但优化编译器将字节码转成机器码也需要消耗一些时间。综合考虑下来,大部分代码以字节码的形式执行,少部分会优化成机器码执行。
值得一提的是,V8引擎的解释器叫Ignition,优化编译器叫TurboFan。这时再去看V8的原理就可能更容易理解了。
JS对象的表示
JS对象是以字典的形式存在,每一个字符串key映射到对应的value。但更底层一点,应该是映射到对应的property属性。回想一下,我们可以通过Object.defineProperty修改对象属性的隐藏属性:value、writable、enumerable和configurable。 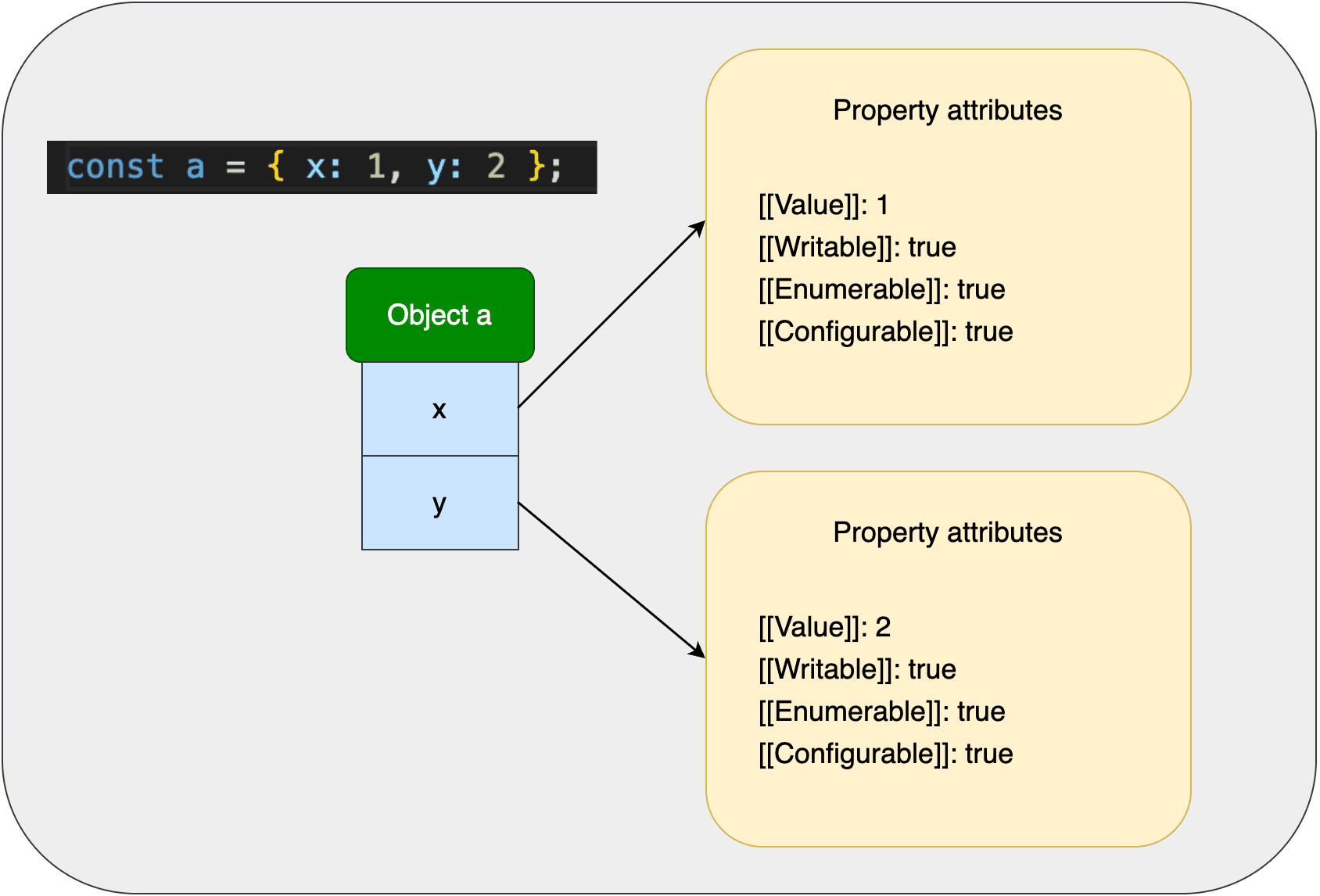 上面的对象
上面的对象a,它的两个属性x、y分别指向对应的property属性,value分别为1和2。
当我们需要创建大量相似的对象时,比如通过下面的构造函数Person出3个实例:
1
2
3
4
5
6
7
8
function Person(name, age) {
this.name = name;
this.age = age;
}
const a = new Person('Thomas', 1);
const b = new Person('John', 2);
const c = new Person('Lucy', 3);
a、b、c三个对象有相同的属性key:name和age,包括writable等隐藏属性也想通,只是value值不同而已。是否可以把这些对象相似的地方拎出来复用,从而减少内存占用?可以的,下面讲到的Shapes就可以给相似对象复用。
Shapes
在学术论文中一般叫Hidden Classes,在V8里叫Maps(跟ES6里的Map不是一个概念)。这里用Shapes表示会更容易理解。
前面通过构造函数Person创建的3个对象有相同的属性结构,可以说它们有相同的Shape。每个对象只保存它的values,然后指向共同的Shape。Shape里每个key都关联了property属性的信息和一个偏移量,通过这个偏移量可以找到JSObject里存储的value值。 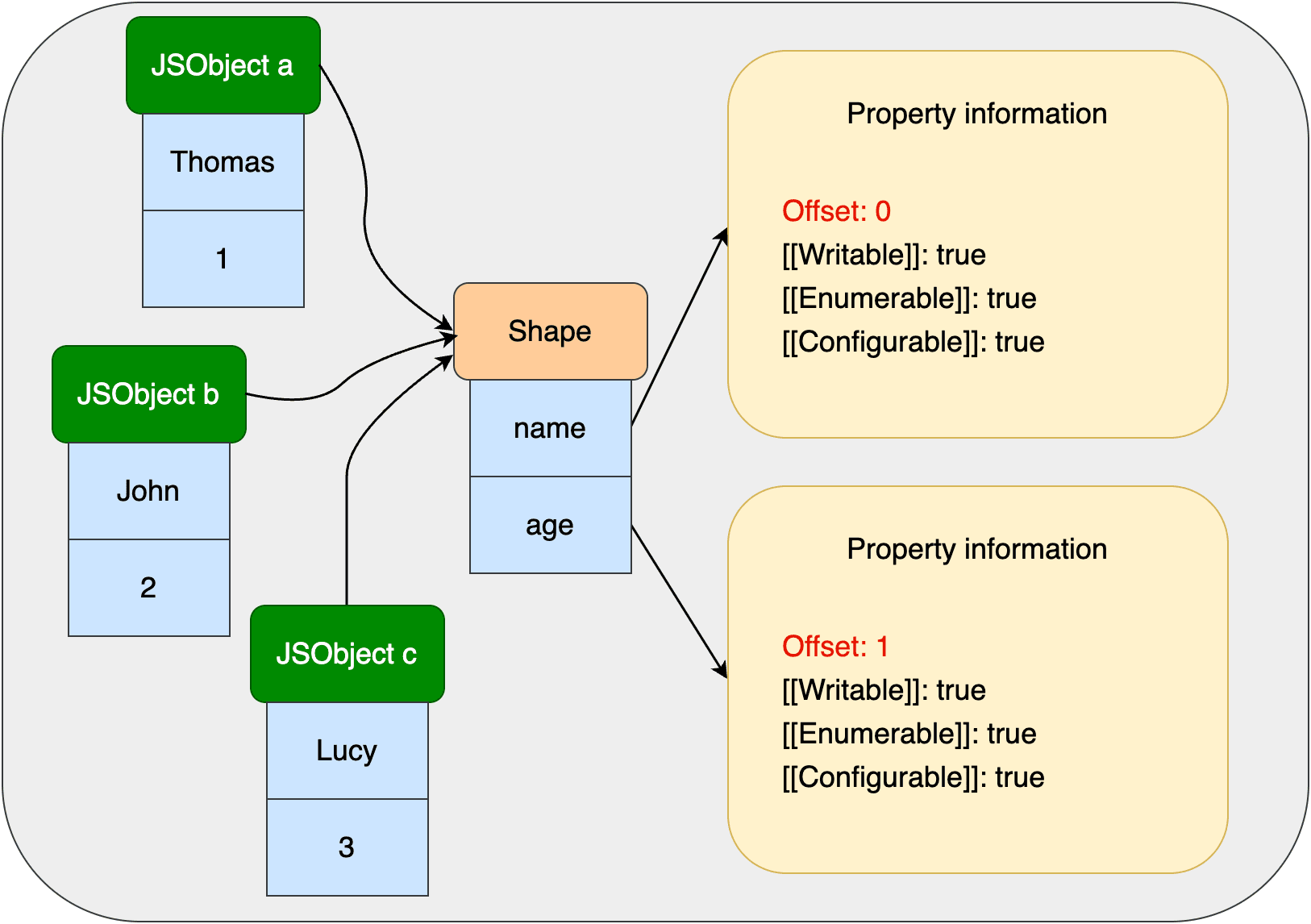
Shape转变链
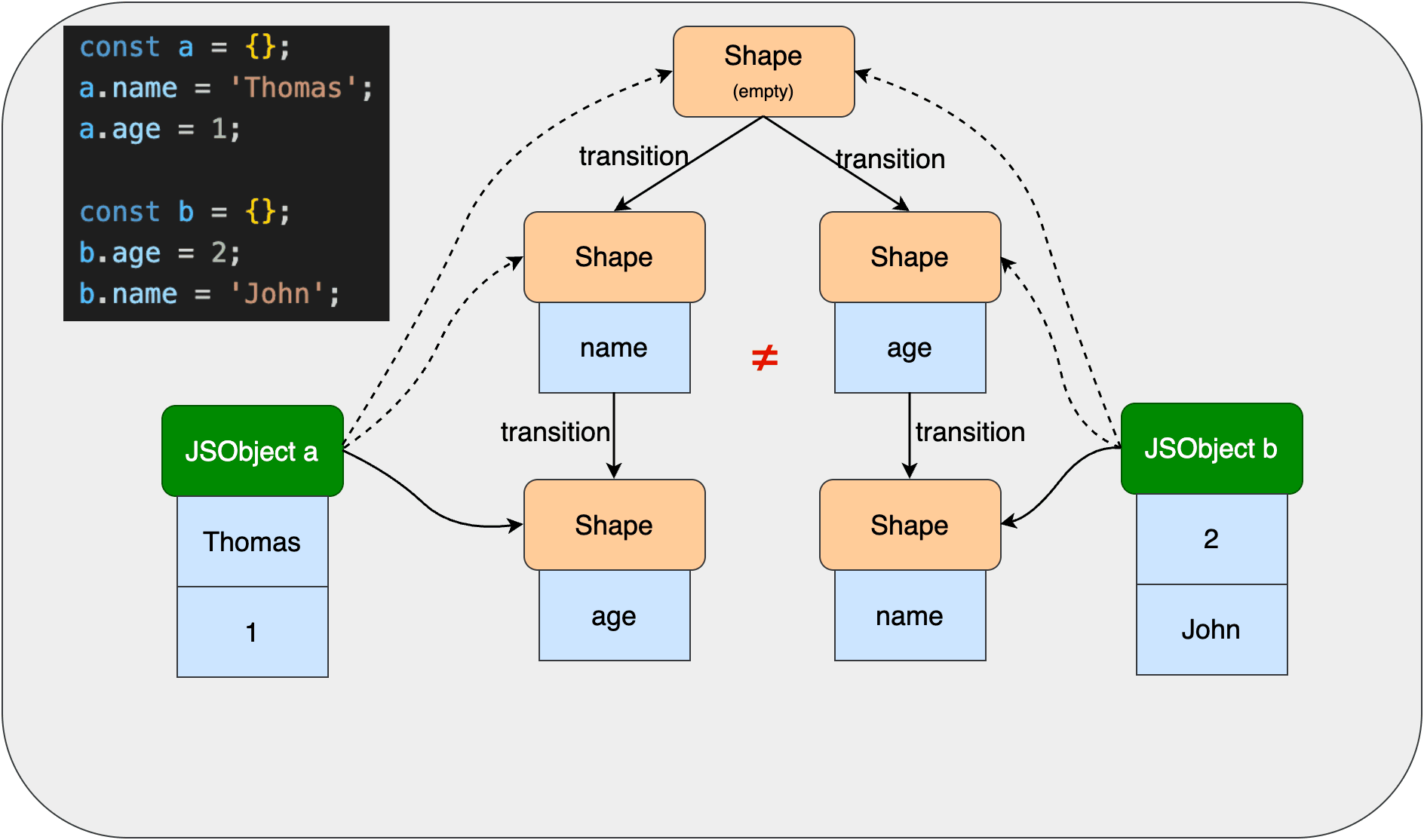
对象动态添加属性会形成Shape转变链。比如下图: 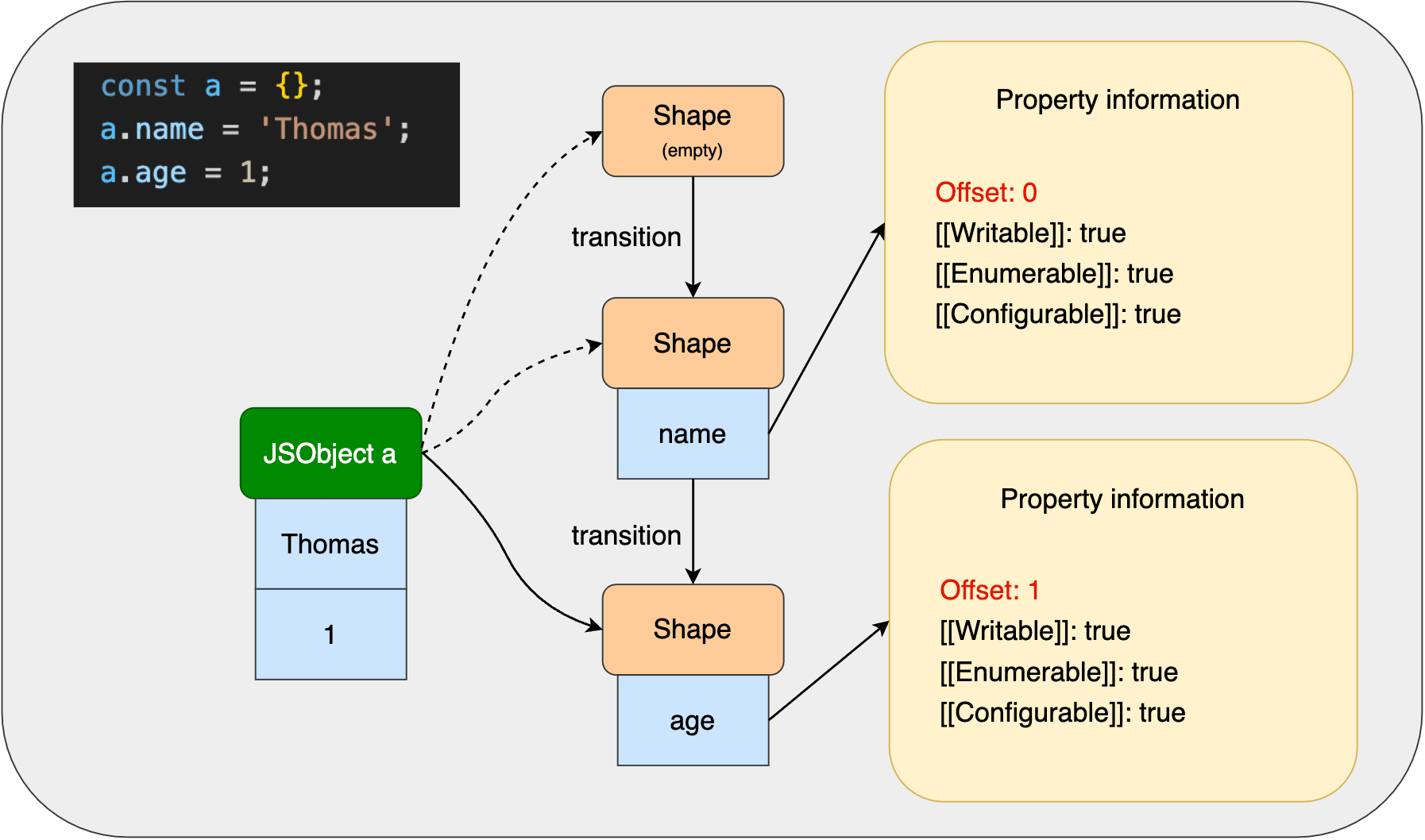 对象
对象a一开始指向一个空Shape,添加name属性后,空Shape转变成含有name的Shape,再添加age属性后,Shape又转变成含有age的Shape。
这里有个问题,就是Shape转变之后,对象a指向最后一个Shape,如果现在要访问a.name,如何找到对应的偏移量和value呢?这个问题后面会解答。
属性不同或者属性添加的顺序不同都会形成不同的Shape转变链。
属性不同时的Shape转变链举例: 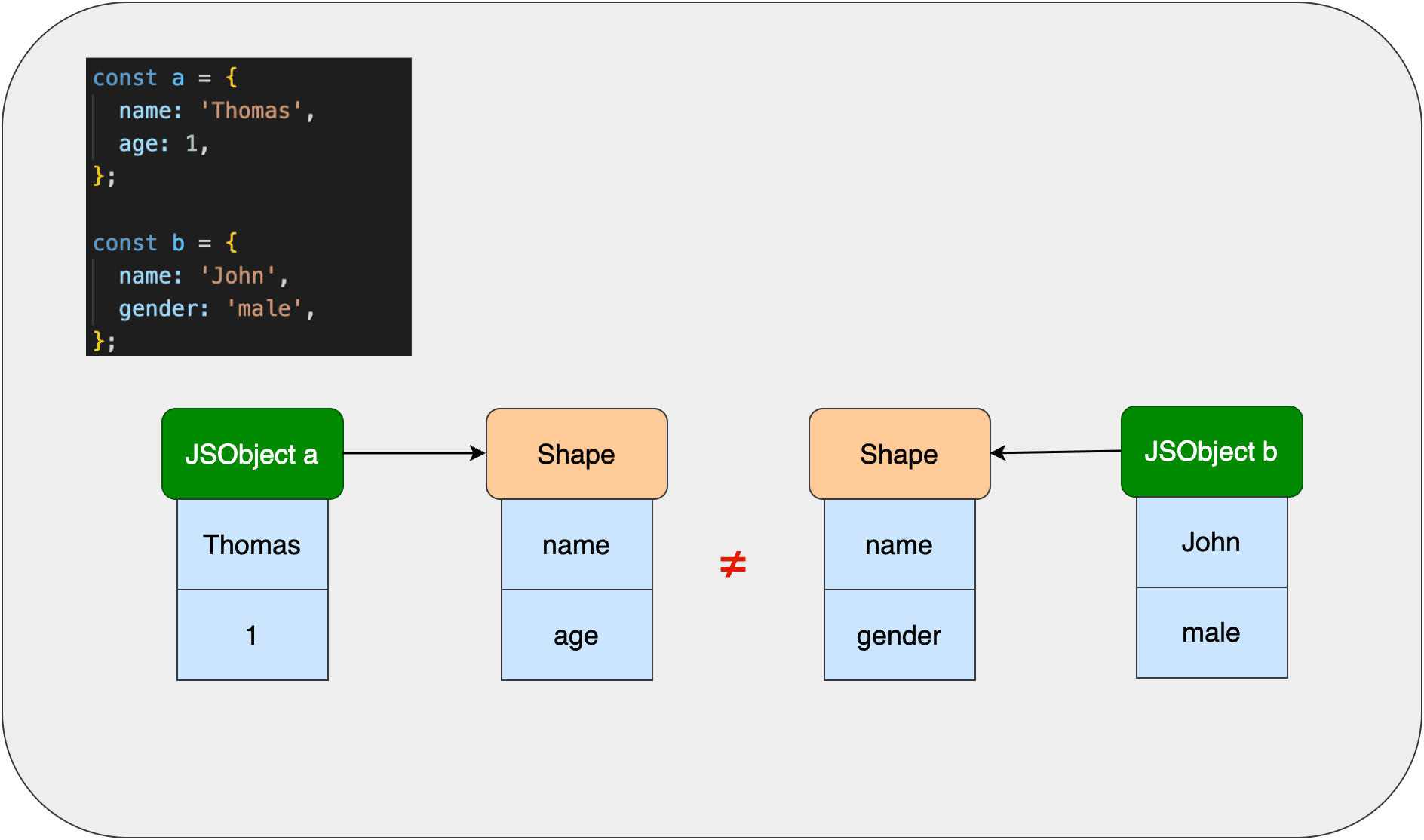
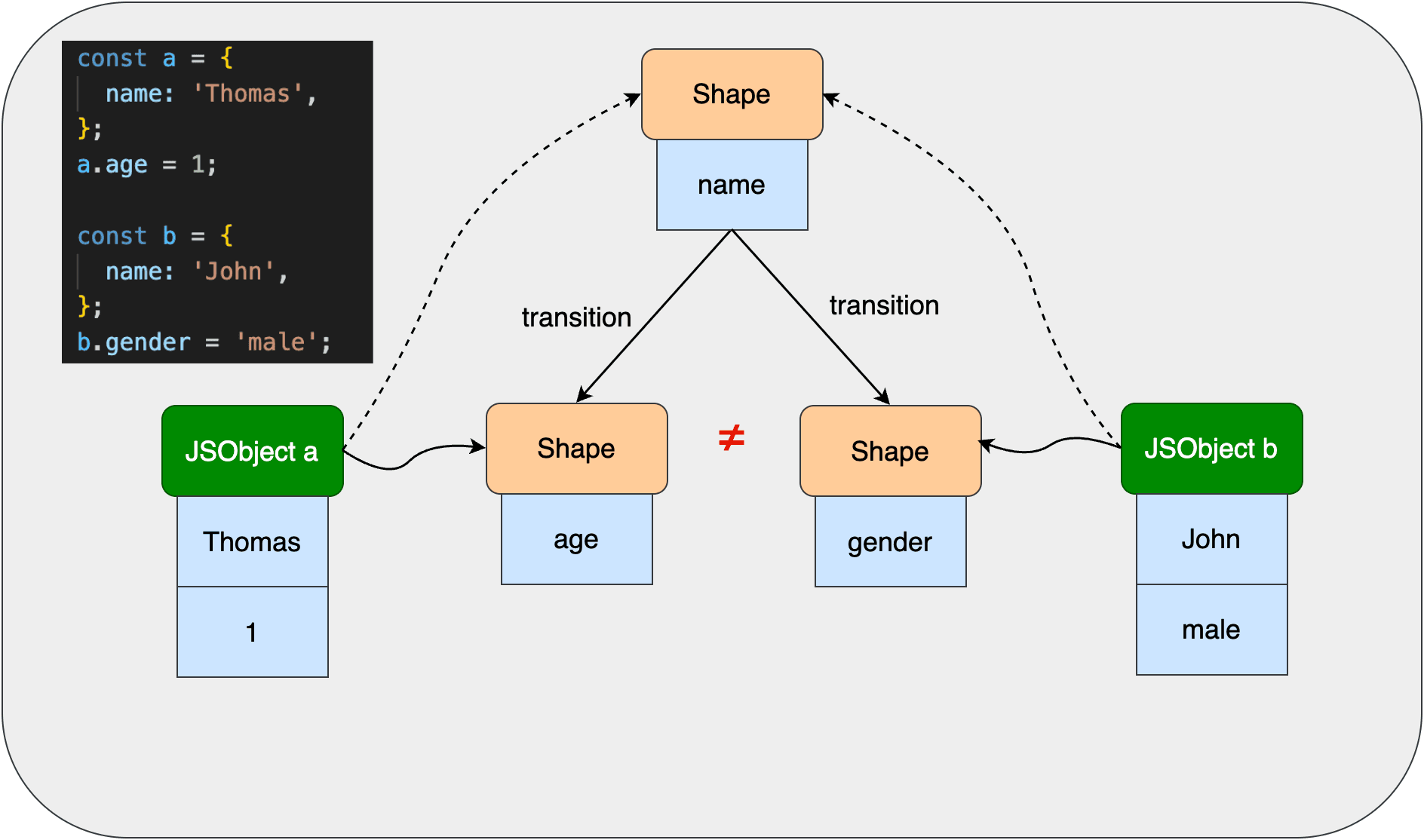 属性添加的顺序不同时的Shape转变链举例:
属性添加的顺序不同时的Shape转变链举例: 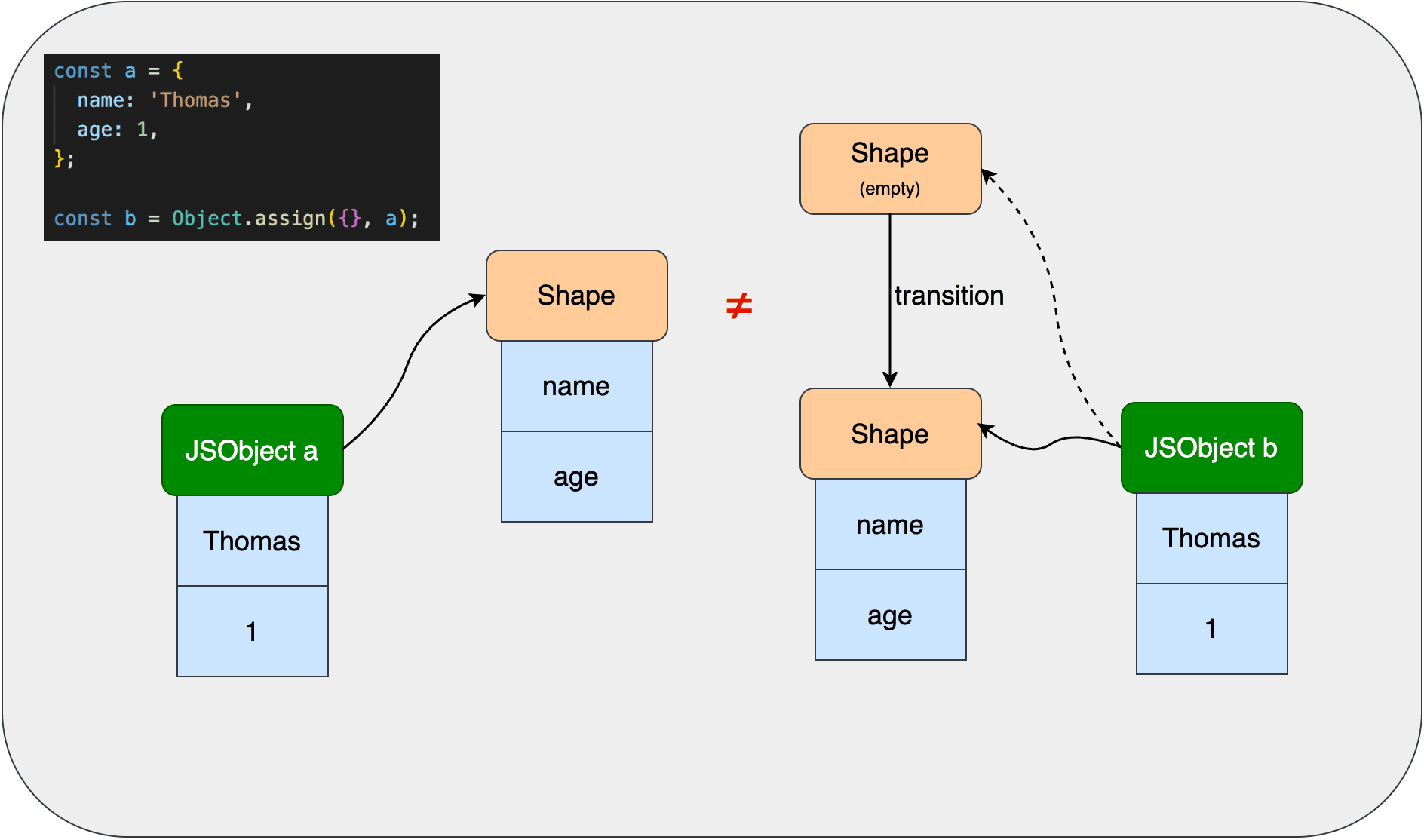
 可以看到,即使
可以看到,即使a、b两个对象最终都有相同的属性值,但它们的Shape转变链是不一样的。
属性访问
前面遗留了一个问题,就是形成Shape转变链之后,对象指向了最后一个Shape,如果需要访问其他对象属性,该如何操作?
一个办法是像下图这样从转变链的反方向去查找: 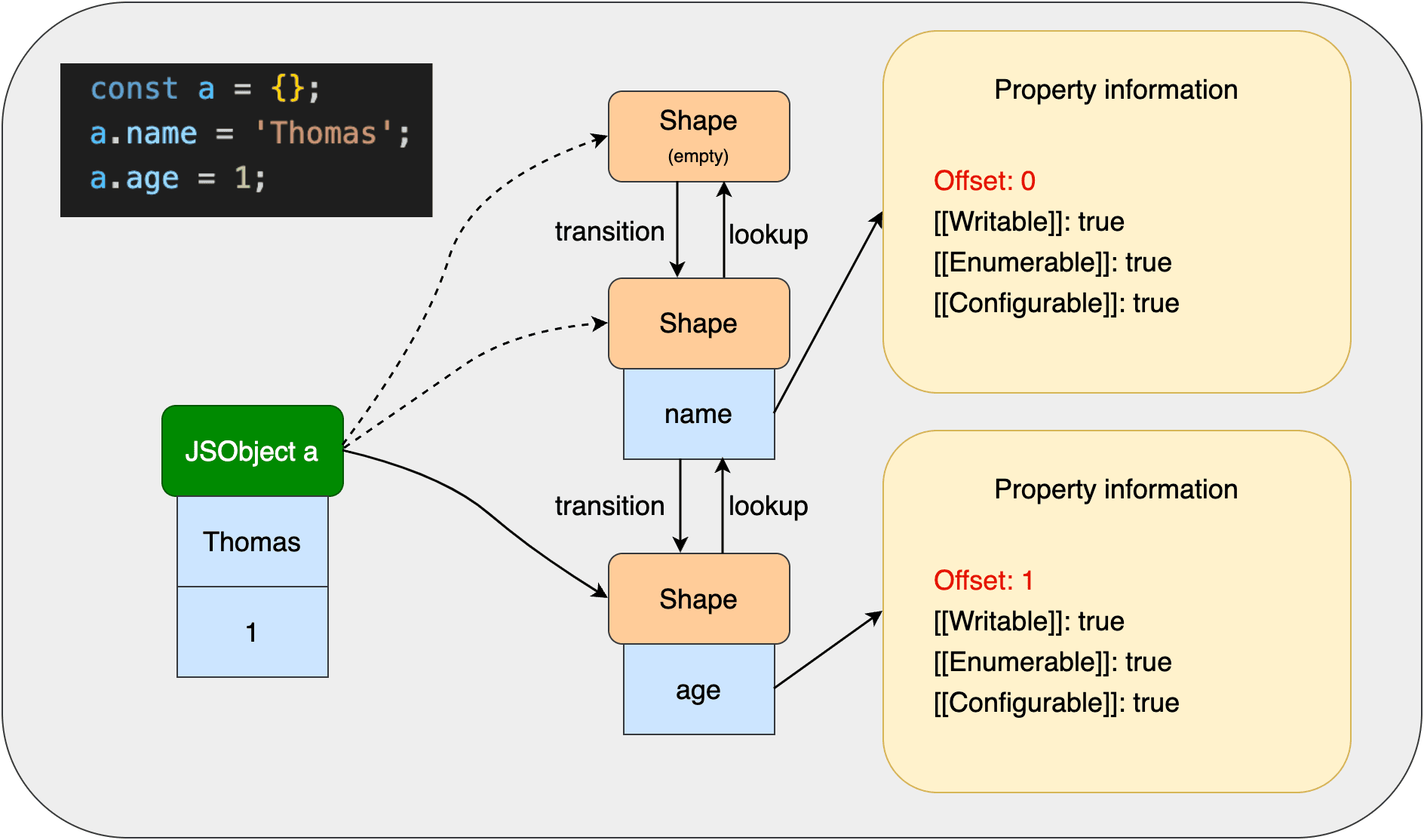 但这样的话,属性访问的时间将会是O(n)复杂度。所以JS引擎通过一个叫
但这样的话,属性访问的时间将会是O(n)复杂度。所以JS引擎通过一个叫ShapeTable的字典,将属性key映射到对应的Shape上,这样属性访问时间就是常数级别。 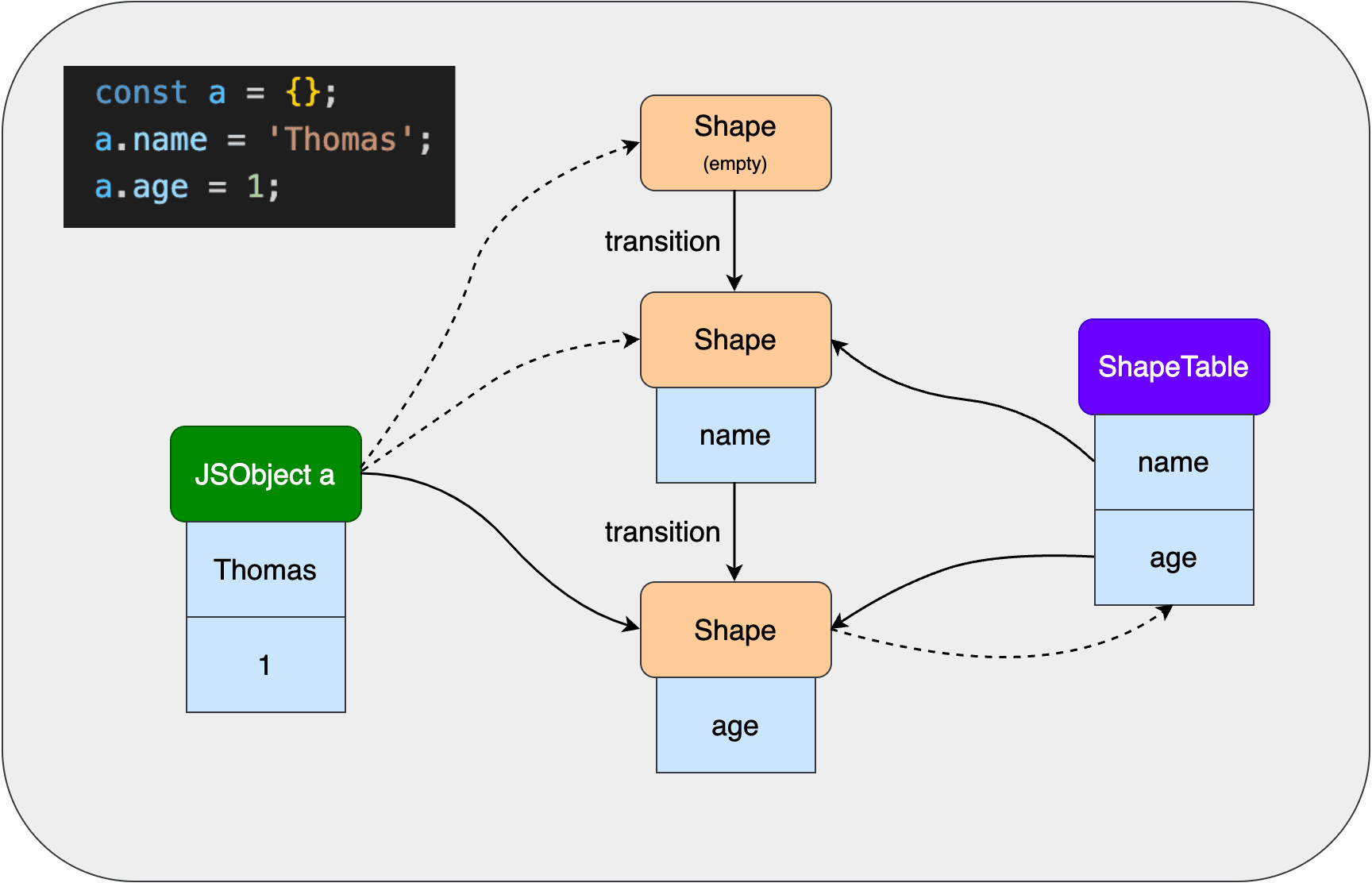
Shapes的作用
为什么JS引擎要大费周章构造Shapes呢?除了通过复用减少内存,更重要的是它为JS引擎的Inline Caches优化提供了反馈信息。
Inline Caches
假设有这样一段代码:
1
2
3
4
5
6
function getName(user) {
return user.name;
}
getName({ name: 'Thomas' });
getName({ name: 'John' });
getName函数获取用户名字,多次调用时传入的user对象有相同的Shapes。
正常来说,属性访问时比较慢的,需要经过Shape转变链和ShapeTable才能找到属性的偏移量(Offset),从而定位到JSObject里的value。
当多次调用getName传入的对象具有相同的Shapes时,JS引擎就会假定以后都会传入类似的对象,这时会把前面的对象的name属性对应的偏移量0缓存起来,下次执行getName时就可以通过缓存的偏移量直接访问到value值。这就是Inline Caches。
当然,Inline Caches推断出错后会回退到最初的属性访问方式。
如何判断对象是否有相同Shapes
经过前面的介绍,我们知道,要想利用JS引擎Inline Caches的优化,就要尽量创建相同Shapes的对象。
而且我们知道如何判断两个对象是否有相同的Shapes(相同属性以及属性添加顺序)。
如果心里还是没底,这里有一个办法,可以利用nodejs判断:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// index.js
const a = {};
a.name = 'Thomas';
a.age = 1;
const b = {};
b.name = 'John';
b.age = 2;
const c = {};
c.age = 3;
c.name = 'Lucy';
console.log(%HaveSameMap(a, b)); // true
console.log(%HaveSameMap(a, c)); // false
1
node --allow-natives-syntax index.js
HaveSameMap是V8的方法,用来判断两个对象的Shapes是否相同,--allow-natives-syntax表示允许使用V8内置的一些方法,其他方法可以参考这里。
可以看到,打印结果和前面的分析是一致的。
Inline Caches优化前后性能差距
我用benchmark.js简单写了个测试用例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
const Benchmark = require('benchmark');
function getName(person) {
return person.name;
}
const suite = new Benchmark.Suite();
suite
.add('没有Inline Caches', () => {
function Person1() {
this.name = 'Thomas';
this.age = 1;
}
function Person2() {
this.name = 'John';
this.age = 2;
}
function Person3() {
this.name = 'Lucy';
this.age = 3;
}
// 不同构造函数new出来的对象Shapes不同
const a = new Person1();
const b = new Person2();
const c = new Person3();
getName(a);
getName(b);
getName(c);
})
.add('有Inline Caches', () => {
function Person1() {
this.name = 'Thomas';
this.age = 1;
}
const a = new Person1();
const b = new Person1();
const c = new Person1();
getName(a);
getName(b);
getName(c);
})
.on('cycle', (event) => {
const benchmark = event.target;
console.log(benchmark.toString());
})
.on('complete', (event) => {
const suite = event.currentTarget;
const fastestOption = suite.filter('fastest').map('name');
console.log(`更快的是:${fastestOption}`);
})
.run();
运行之后得到以下输出:
1
2
3
没有Inline Caches x 284,413 ops/sec ±1.04% (92 runs sampled)
有Inline Caches x 800,217 ops/sec ±0.96% (91 runs sampled)
更快的是:有Inline Caches
有Inline Caches是没有Inline Caches的2.8倍运行速度,对象越复杂性能差距越大。
总结
- 属性相同和属性添加顺序相同的对象具有相同的Shapes;
- 重复使用有相同Shapes的对象会触发JS引擎的
Inline Caches优化; - nodejs的
--allow-natives-syntaxflag和V8的HaveSameMap方法可以帮助我们判断两个对象的Shapes是否相同。