
缘由
作为js语言的代码检查工具,eslint几乎会出现在所有的前端项目中,而prettier作为一个代码格式化的工具,功能上与eslint有重叠部分。对于js中semicolons、comma-dangle等代码规则,eslint能够跟prettier一样autofix,这是否意味着我们工程里只要配置eslint就够了?如果可以这样,不失为一件美事。可惜的是,对于prettier能够完美处理的行字数超出限制的问题,eslint的max-len却只能提示错误,不能autofix。
关于max-len的问题,有人在github提过issue,得到eslint贡献者的回复是不解决,原因主要是:
- 难以决定在哪里断行,autofix会过于主观;
- 不安全,容易与其他规则冲突。
可是,为什么prettier就知道该在哪里断行?eslint实现自动断行难在哪里?eslint规则冲突怎么处理? 本文将通过prettier和eslint的原理对比,尝试解答以上问题,希望看到最后你能豁然开朗。
prettier原理
介绍
prettier是一个适用于多种语言的代码格式化工具,对保持团队内代码风格的一致性很有帮助。自从用上了prettier,我写代码就完全不用关心缩进、空格、换行等问题,思维只专注于代码逻辑,开发效率提升不少。 关于prettier,官网有这样一段描述:

这里我只关心第一点和第四点,opinionated,谷歌翻译过来的意思是“自以为是的”。说人话就是,prettier给我们提供了一套它认为合理的代码风格,我们只要按它的风格来就好了。当然,prettier还是提供了一定的配置项(虽然很少)给我们,让开发者拥有一定的自由度配出合乎自己习惯的代码规范。 prettier只关心代码风格,不关心代码质量。所以它不像eslint那样有no-undefined、prefer-const这样的规则,能发现代码中潜在的错误或者可以优化的点,并给出建议。对于代码中的语法错误,prettier无能为力。
源码分析
prettier的原理很简单,关键代码在src/main/core.js的coreFormat函数中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
function coreFormat(originalText, opts, addAlignmentSize = 0) {
// 省略极端情况的return
// 将源码解析成语法树
const { ast, text } = parser.parse(originalText, opts);
// 省略部分代码
const astComments = attachComments(text, ast, opts);
// 语法树每一个节点应用opts中的semi、trailing-comma等规则,生成包含type、contents等的描述对象
const doc = printAstToDoc(ast, opts, addAlignmentSize);
// 根据上面生成的doc对象中的各种type和opts的printWidth,处理各种情况下的换行
// 因为semi、trailing-comma等规则影响文本长度,所以必须比printWidth规则早处理
const result = printDocToString(doc, opts);
return {
formatted: result.formatted,
cursorOffset: -1,
comments: astComments,
};
}
一图胜千言  prettier很巧妙地忽略了源码中的各种格式,利用语法树提取关键内容,再应用规则,最后处理换行。所以,无论源码中是2个空格缩进还是4个空格缩进,处理后的结果都是一样。 值得一提的是,对于object类型来说,每次格式处理得到的产物不一定相同,情况有以下几种:
prettier很巧妙地忽略了源码中的各种格式,利用语法树提取关键内容,再应用规则,最后处理换行。所以,无论源码中是2个空格缩进还是4个空格缩进,处理后的结果都是一样。 值得一提的是,对于object类型来说,每次格式处理得到的产物不一定相同,情况有以下几种:
- 单行对象
- 没有超出最大行宽,处理后保持单行对象
- 超出最大行宽,换行
- 多行对象
{和第一个属性不在一行,换行处理{和第一个属性在一行,变成单行对象是否会超出最大行宽- 会,换行处理
- 不会,转成单行对象
以上各种情况对应的代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
// 1.a before === after
const user1 = { name: 'Cyndi Wang', age: 18 };
// 1.b before
const user2 = { name: 'Cyndi Wang', age: 18, songs: '爱你、第一次爱的人、当年、睫毛弯弯' };
// 1.b after
const user2 = {
name: 'Cyndi Wang',
age: 18,
songs: '爱你、第一次爱的人、当年、睫毛弯弯',
};
// 2.a before
const user3 = {
name: 'Cyndi Wang', age: 18 };
// 2.a after
const user3 = {
name: 'Cyndi Wang',
age: 18,
};
// 2.b.i before
const user4 = {name: 'Cyndi Wang',
age: 18,
songs: '爱你、第一次爱的人、当年、睫毛弯弯',
};
// 2.b.i after
const user4 = {
name: 'Cyndi Wang',
age: 18,
songs: '爱你、第一次爱的人、当年、睫毛弯弯',
};
// 2.b.ii before
const user5 = {name: 'Cyndi Wang',
age: 18,
};
const user5 = { name: 'Cyndi Wang', age: 18 };
eslint原理
这里不会讲如何配置eslintrc,也不会详细讲eslint的插件机制,这些自己去看文档就好了。
源码分析
从eslint的package.json文件开始,结合debugger,一路分析,源码调用链如下: 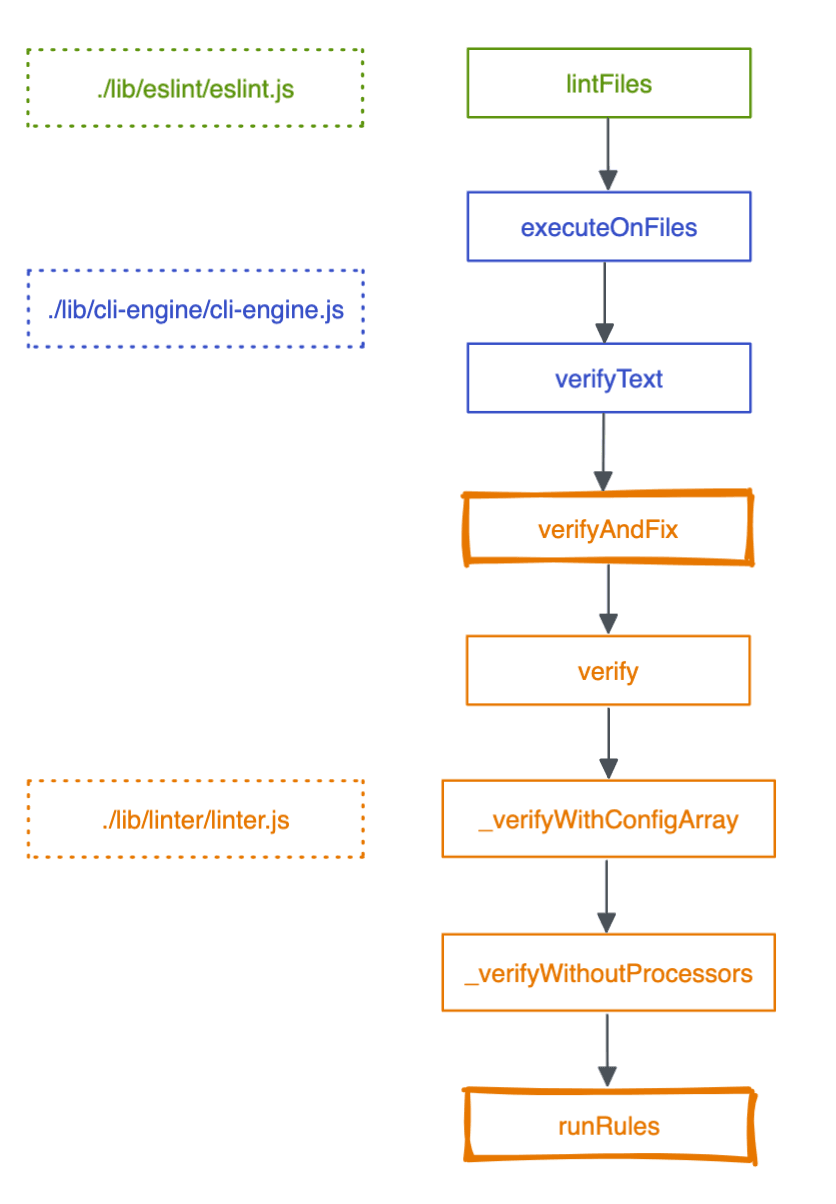 其中核心的是
其中核心的是linter.js中的verifyAndFix和runRules方法。 先来讲runRules方法,以下是精简后的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
function runRules(sourceCode, configuredRules, ruleMapper, parserName, languageOptions, settings, filename, disableFixes, cwd, physicalFilename) {
const emitter = createEmitter();
const nodeQueue = [];
let currentNode = sourceCode.ast;
// 遍历语法树,把各个节点的进出都记录下来
Traverser.traverse(sourceCode.ast, {
enter(node, parent) {
node.parent = parent;
nodeQueue.push({ isEntering: true, node });
},
leave(node) {
nodeQueue.push({ isEntering: false, node });
},
visitorKeys: sourceCode.visitorKeys
});
// 所有规则共同的上下文,包括parserOptions等配置以及getSourceCode等方法
const sharedTraversalContext = Object.freeze(
// ...
);
const lintingProblems = [];
Object.keys(configuredRules).forEach(ruleId => {
// ...
// 获取ruleId(比如semi)对应的规则配置
const rule = ruleMapper(ruleId);
// ...
const messageIds = rule.meta && rule.meta.messages;
let reportTranslator = null;
// 构造规则的上下文
const ruleContext = Object.freeze(
Object.assign(
Object.create(sharedTraversalContext),
{
id: ruleId,
options: getRuleOptions(configuredRules[ruleId]),
// context.report会执行该方法,生成problem对象
report(...args) {
if (reportTranslator === null) {
reportTranslator = createReportTranslator({
ruleId,
severity,
sourceCode,
messageIds,
disableFixes
});
}
const problem = reportTranslator(...args);
// ...
lintingProblems.push(problem);
}
}
)
);
// 执行规则的create方法
const ruleListeners = createRuleListeners(rule, ruleContext);
// ...
// create返回的对象ruleListeners的每一个key都是一个选择器
// 为每一个选择器创建事件监听
Object.keys(ruleListeners).forEach(selector => {
const ruleListener = timing.enabled
? timing.time(ruleId, ruleListeners[selector])
: ruleListeners[selector];
emitter.on(
selector,
addRuleErrorHandler(ruleListener)
);
});
});
const eventGenerator = nodeQueue[0].node.type === "Program"
? new CodePathAnalyzer(new NodeEventGenerator(emitter, { visitorKeys: sourceCode.visitorKeys, fallback: Traverser.getKeys }))
: new NodeEventGenerator(emitter, { visitorKeys: sourceCode.visitorKeys, fallback: Traverser.getKeys });
// 遍历上面存储的nodeQueue,emit事件
nodeQueue.forEach(traversalInfo => {
currentNode = traversalInfo.node;
try {
if (traversalInfo.isEntering) {
eventGenerator.enterNode(currentNode);
} else {
eventGenerator.leaveNode(currentNode);
}
} catch (err) {
err.currentNode = currentNode;
throw err;
}
});
return lintingProblems;
}
结合eslint插件开发的方式,上面这段代码就更好理解了。 开发过eslint插件的同学都知道,定义rule的标准形式是导出以下对象:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
// 自定义rule
module.exports = {
meta: {
type: 'layout',
docs: {
// ...
},
fixable: 'code',
messages,
schema: [
// ...
],
},
// createRuleListeners内部执行该方法
create(context) {
return {
// ObjectExpression就是一个选择器,也作为一个事件名创建事件监听
// 语法树遍历到该类型的节点时会触发事件回调
ObjectExpression(node) {
// ...
// report方法会生成problem并收集到lintingProblems数组里
context.report({
node,
message: 'This is an error.',
fix(fixer) {
// 返回fixer调用方法的结果
},
});
},
};
},
};
meta是规则的一些描述信息,create方法是规则的核心实现。通过事件监听,eslint让各种规则勾到语法树遍历的过程中,然后通过一次语法树的遍历就将所有problem检查出来。 problem包含了错误提示、错误的位置、如何修复等必要信息,配合控制台、VSCode插件、npm scripts等就能显示eslint错误提示、错误位置加红色下划线、自动修复等功能。 runRules方法分析完,再来讲讲调用它的verifyAndFix,源码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
class Linter {
// ...
verifyAndFix(text, config, options) {
let messages = [],
fixedResult,
fixed = false,
passNumber = 0,
currentText = text; // currentText开始是源码
const debugTextDescription = options && options.filename || `${text.slice(0, 10)}...`;
const shouldFix = options && typeof options.fix !== "undefined" ? options.fix : true;
// 每次循环,检查出currentText的所有错误,并尝试修复,然后用修复的结果更新currentText
// 不需要fix,只循环1次,需要fix,至少循环2次
// 跳出循环的条件,满足其一即可
// 1. 有语法错误
// 2. 没有要fix的错误
// 3. 修复超过10次
do {
passNumber++;
// 检查错误
messages = this.verify(currentText, config, options);
// 修复问题
fixedResult = SourceCodeFixer.applyFixes(currentText, messages, shouldFix);
// 如果有语法错误,跳出循环,这时fixedResult.output为空字符串
if (messages.length === 1 && messages[0].fatal) {
break;
}
// 任何一个修复执行了,就认为整个源文件已经修复了
fixed = fixed || fixedResult.fixed;
// 用修复的产物替代源码
currentText = fixedResult.output;
} while (
// fixedResult.fixed为false说明已经没有需要fix的问题
fixedResult.fixed &&
passNumber < MAX_AUTOFIX_PASSES // 最多循环10次,避免规则冲突时死循环
);
// 如果最后一次执行了修复,对于冲突的规则(假设刚好有semi和no-semi两个相反的规则)
// SourceCodeFixer.applyFixes执行后遗留的问题中移除了semi和no-semi这两个
// 但是因为冲突的原因,实际没起到修复的效果,遗留的问题应该包含semi和no-semi才对
// 另外,遗留的问题中的位置信息可能不正确
// 所以需要再试执行verify以得到最新的错误
if (fixedResult.fixed) {
fixedResult.messages = this.verify(currentText, config, options);
}
// 只要有一次修复,就认为已经修复
fixedResult.fixed = fixed;
fixedResult.output = currentText;
return fixedResult;
}
}
看源码注解应该很清楚了,verifyAndFix方法通过do...while循环多次执行检查和修复,不断更新currentText。为避免规则冲突导致死循环,提供了退出机制。 修复的逻辑在SourceCodeFixer.applyFixes中实现,精简后的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
SourceCodeFixer.applyFixes = function(sourceText, messages, shouldFix) {
if (shouldFix === false) {
// return
}
const remainingMessages = [],
fixes = [],
bom = sourceText.startsWith(BOM) ? BOM : "",
text = bom ? sourceText.slice(1) : sourceText;
let lastPos = Number.NEGATIVE_INFINITY,
output = bom;
function attemptFix(problem) {
const fix = problem.fix;
const start = fix.range[0];
const end = fix.range[1];
// 如果重叠或者负区间,保留问题
if (lastPos >= start || start > end) {
remainingMessages.push(problem);
return false;
}
// ...
// 根据fix信息,拼接结果
output += text.slice(Math.max(0, lastPos), Math.max(0, start));
output += fix.text;
lastPos = end;
return true;
}
// 问题分类:要修复和不要修复的
messages.forEach(problem => {
if (Object.prototype.hasOwnProperty.call(problem, "fix")) {
fixes.push(problem);
} else {
remainingMessages.push(problem);
}
});
if (fixes.length) {
let fixesWereApplied = false;
// 根据修复的range排序,从前到后修复问题
for (const problem of fixes.sort(compareMessagesByFixRange)) {
if (typeof shouldFix !== "function" || shouldFix(problem)) {
attemptFix(problem);
// 规则冲突时依然认为已经修复
fixesWereApplied = true;
} else {
remainingMessages.push(problem);
}
}
// 把所有修复都执行完之后,拼接剩余的文本
output += text.slice(Math.max(0, lastPos));
// fix之后,messages不包含修复掉的problem
return {
fixed: fixesWereApplied,
messages: remainingMessages.sort(compareMessagesByLocation),
output
};
}
// 没有要修复的问题
return {
fixed: false,
messages,
output: bom + text
};
};
原理就是找出需要修复的问题,根据需要修复的range排序,从小到大执行修复。修复过程就是根据源码(text)、range信息和替换文本,拼接出产物(output)。同时,lastPos作为位置指针不断移动,每修复一个规则问题拼接一段代码,最后产出整个文本的修复结果。 至此,eslint核心原理已经分析完,我们也应该能回答这两个问题了:
1. 规则如何执行?
通过事件监听,遍历语法树时执行context.report方法,收集问题。
2. 如何处理规则冲突?
假设有跟semi完全相反的规则no-semi,并且eslint配置如下:
1
2
3
4
5
6
module.exports = {
rules: {
'semi': ["error", "always"], // 强制语句末加分号
'no-semi': ["error", "always"], // 强制语句末不加分号
}
}
这两个规则是冲突的,对于import { union } from 'lodash'这个语句,我们应用--fix,eslint会反复在句末添加、移除分号10次,然后放弃修复。因为是偶数次处理,所以代码没有任何变化。 这么看来,eslint并没有用什么巧妙的方法去解决规则冲突,反而有点返璞归真,多次尝试修复,不行的话交给用户手动处理。
如何与prettier集成?
eslint-config-prettier关闭掉eslint格式化相关的规则,eslint-plugin-prettier提供prettier/prettier规则,让eslint调用prettier进行格式化处理。
小结
| prettier | eslint | |
|---|---|---|
| 能力范围 | 代码风格 | 代码风格和代码质量 |
| 格式化步骤 | 没有错误提示,直接格式化整个文件 |
- 提示错误位置和信息
- 加上
--fix参数或者IDE配合才能做到autofix | | 是否自动修复 | 完全自动修复 | 部分自动修复 | | 产物一致性 | 完全一致(除了多行对象) | 不保证一致 |
为什么max-len不能autofix?
有了上面的分析,现在就可以来说说eslint实现max-len的autofix有多难了。
1. 规则执行顺序
与prettier先处理其他规则,得到的产物再应用printWidth不同。eslint的规则执行是按规则作用的range的先后来的,而且是一次性执行完所有修复才更新产物。max-len规则受semi、object-curly-spacing等规则影响,应该像prettier那样作用于其他规则的产物才行,可是eslint规则的执行顺序不允许。
2. 场景复杂
我之前尝试过去实现max-len的autofix,发现要处理的场景太多,逻辑太复杂。 就拿我们常见的import语句来说,我们在写代码时以下各种情况都可能出现。
1
2
3
4
5
6
7
8
9
10
// 场景1
import React, { useState, useCallback, useEffect } from 'react'; // 超出最大字数
// 场景2
import React, {
useState, useCallback, useEffect } from 'react'; // 超出最大字数
// 场景3
import React, {
useState, useCallback, // 超出最大字数
useEffect
} from 'react';
场景1还比较好处理,因为name import两侧的括号在同一行。但是场景2、场景3就比较复杂了。此外,还有其他场景还没列举呢。 这么看来,prettier就聪明得多了,管你写法再多,它都忽略掉,从而绕过了大难题。
3. API能力有限
这跟上面两点是关联的。因为场景复杂,需要做的分析很多,加上规则执行顺序的问题、ObjectExpression等语法树选择器关注的点比较小,很难收集足够的信息去做分析,也就很难检查出问题、确定错误位置以及给出修复处理。据我理解,eslint目前的API并不足以支撑max-len规则的autofix。
4. 规则冲突
正如eslint的核心开发者所说,max-len很容易跟其他规则发生冲突。一是max-len作用范围比较广,二是eslint内置的规则本来就很多,还允许用户自定义规则,这就大大提高了与max-len冲突的概率。而我们能做的通过关闭其中一个或多个规则来避免冲突。我们会因为max-len而舍弃array-bracket-newline等规则吗?到头来可能还是放弃max-len吧。
小结
上面说的这些问题,归根结底都是eslint框架设计的问题,但我并不是要说eslint做得有多烂,连max-len的autofix都不支持。而是想说,eslint的设计理念跟prettier大相径庭,这就导致了eslint要实现max-len的autofix很困难。或许eslint最关心的还是如何发现代码中的坏味道,并给出建议吧,autofix并不需要做得很完美。
总结
本文由一个社区的讨论为切入点,对比了prettier和eslint的原理,发现两者的设计理念大不相同。这也直接导致了prettier能完美处理printWidth而eslint至今没有实现max-len的autofix。 文中大多数分析都是来自于个人的理解,可能有不够合理的地方。如果你发现有错误的地方,欢迎指正。